Modern Operating Systems 笔记 - Deadlocks
Resources
A preemptable resource is one that can be taken away from the process owning it with no ill effects.
A nonpreemptable resource is one that cannot be taken away from its current owner without causing the computation to fail.
Resource Acquisition
- Request the resource.
- Use the resource.
- Release the resource.
A possible implementation:
downon the semaphore to aquire the resource.- using the resource.
upon the semaphore to release the resource.
Introduction to Deadlocks
A set of processes is deadlocked if each process in the set is waiting for an event that only another process in the set can cause.
Conditions for Resource Deadlocks:
- Mutual exclusion condition.
- Hold and wait condition.
- No preemption condition.
- Circular wait condition.
Strategies used for dealing with deadlocks:
- Just ignore the problem.
- Detection and recovery.
- Dynamic avoidance by careful resource allocation.
- Prevention, by structurally negating one of the four required conditions.
The Ostrich Algorithm
Just ignore the problem when the deadlock isn't that often, that serious.
Few current systems will detect the deadlock between CD-ROM and printer.
Deadlock Detection and Recovery
Deadlock Detection with One Resource of Each Type
For such a system, we can construct a resource graph of the resources and processes. If this graph contains cycles, a deadlock exists.
Deadlock Detection with Multiple Resources of Each Type
E is the existing resource vector, which gives the total nmber of instances of each resource in existence.
A is the available resource vector, which gives the number of instances of resource that are currently available.
C is the current allocation matrix, the i-th row of C tells how many instances of each resource class $P_i$ currently holds.
R is the request matrix, holds the number of instances of resource that processes want.
The following algorithm will mark all processes that are not deadlocked.
- Look for an unmarked process, $P_i$, for which the i-th wor of R is less than or equal than A.
- If such a process is found, add the i-th row of C to A, mark the process, and go back to step 1.
- If no such process exists, the algorithm terminates.
Recovery from Deadlock
- Recovery from Preemption
- Recovery through Rollback, which requires processes periodically checkpointed(memory image and resource state).
- Recovery through Killing Processes.
Deadlock Avoidance
Resource Trajectories
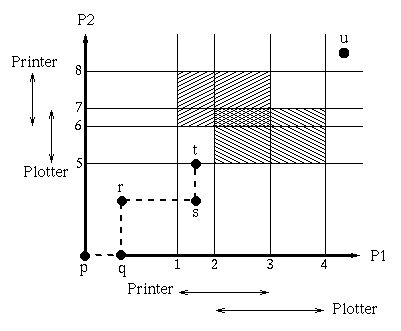
Safe and Unsafe States
A state is said to be safe if there is some scheduling order in which every process can run to completion even if all of them suddenly request their maximum number of resources immediately.
It worth nothing that an unsafe state is not a deadlocked state. The system can run for a while and one process can even complete. The difference between a safe state and an unsafe state is that from a safe state the system can guarantee that all processes will finish; from an unsafe state, no such guarantee can be given.
The Banker's Algorithm for a Single Resource
This Algorithm considers each request as it occurs, and sees if granting it leads to a safe state. If it does, the request is granted; otherwise, it is postponed until later.
The Banker's Algorithm for Multiple Resources
- Look for a row, R, whose unmet resource needs are all smaller than or equal to A. If no such row exists, the system will eventually deadlock since no process can run to completion.
- Assume the process of the row chosen requests all the resources it needs and finishes. Mark that process as terminated and add all its resources to the A vector.
- Repeat steps 1 and 2 until either all processes are marked terminated or no process is left whose resource needs can be met.
Deadlock Prevention
| Condition | Approach |
|---|---|
| Mutual exclusion | Spool everything |
| Hold and wait | Request all resources initially |
| No preemption | Take resources away |
| Circular wait | Order resources numerically |
Other Issues
two-phase locking
- In the first phase, the process tries to lock all the records it needs, one at a time.
- If it succeds, it begins the second phase, performing its updates and releasing the locks.
- If during the first phase, some record is already locked, the process just release all its locks and starts the first phase all over.
conmunication deadlocks, unlike resource deadlocks, these are caused by communication errors.
livelock, polling(busy waiting) processes uses up its CPU quantum without making progress but also without blocking.
Starvation, some policy is needed to make a decision about who gets which resource when. This policy may lead to some processes never getting service even though they are not deadlocked.
Starvation can be avoided by using a first-come, first-served, resource allocation policy.
本文采用 知识共享署名 4.0 国际许可协议(CC-BY 4.0)进行许可,转载注明来源即可: https://harttle.land/2013/12/12/modern-os-deadlocks.html。如有疏漏、谬误、侵权请通过评论或 邮件 指出。