概念建模与数据库设计
数据库概述
数据库与DBMS软件构成 数据库系统,为一组用户提供服务,称为 幕前角色 (数据库管理员、设计者、最终用户、系统分析员、应用程序员)。除了数据库用户,还有 幕后工作者 (DBMS系统设计者、实现者、工具开发者、操作和维护人员)提供支持。
数据模型包括三部分:高层的概念数据模型、低层的物理数据模型、之间的表示数据模型。
数据库三层模式体系结构:内层为内模式,描述物理存储结构;概念层为概念模式,描述数据库结构;外层/视图层为外模式/用户视图,描述特定用户感兴趣的一部分数据库。
SDL(storage definition language)定义内模式,VDL(view definition language)定义外模式,DDL(data definition language)定义定义概念模式,而DML(data manipulation language)定义了数据操纵的集合。SQL(structed query language)是一种综合性的关系数据库语言,包括DDL, VDL和DML语言的功能。
DML有两种类型。高层的非过程DML,是面向集合的(set-oriented,set-at-a-time),属于描述性的语言;低层的DML是面向过程的(record-at-a-time)。交互式的DML称为 查询语言 。
DBMS的组建模块如下图:
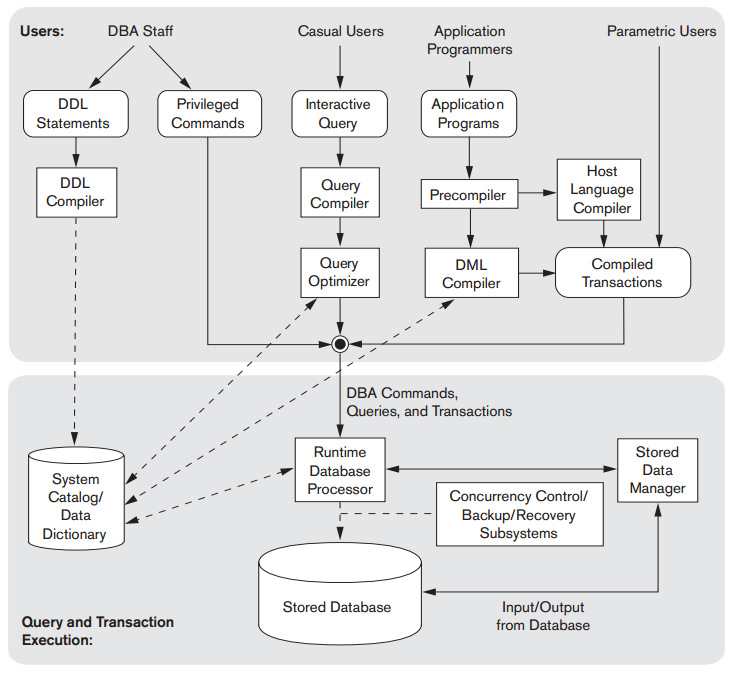
在DBMS的客户机-服务器体系结构中,客户机与查询服务器(事务服务器、SQL服务器)之间首先建立ODBC(open database connectivity),它提供了一组API。(存在面向java的JDBC标准)。
数据模型有多种:关系数据模型、对象数据模型、分层数据模型、网状数据模型。基于这些数据模型,可以把DBMS分为:关系模型、对象数据模型、对象-关系数据模型、层次数据模型、网状数据模型。
实体联系模型
实体联系模型 (Entity-Relationship model)是广泛使用的高级概念数据模型,其图形表示法为 E-R图 。数据库设计的基本步骤:
- 需求汇集和分析。记录数据需求与功能需求。
- 对功能需求进行功能分析。
- 生成高层事务规范。
- 应用程序设计,事务实现。
- 对数据需求进行概念设计。
- 生成概念模式(高层数据模型)
- 逻辑设计,生成逻辑模式(实现数据模型)
- 物理设计,生成内模式。
实体 是ER模型的基本对象,是现实世界中独立存在的事物, 实体类型 是一个具有相同属性的实体的集合。在数据库特定时间某个类型的所有实体集合称为 实体集 。实体具有属性。 复合属性 由 简单(原子)属性 构成; 多值属性 为同时存在多个值的属性; 派生属性 由 存储属性 计算得到; 复杂属性 为复合属性和多值属性的嵌套。
弱实体类型 不具有键属性,必须通过联系依赖于具有键属性的 强实体类型 。
联系 为ER模型中实体属性间的参照关系。实体间的 联系类型 在这些类型的实体间定义了一个关联的集合,称为 联系集 ,由 联系实例 构成。联系类型的 度 是指参与联系的实体类型个数。度为2的联系类型称为 二元联系 。
二元联系的 基数比 指定了一个实体能够参与的联系实例的最大个数。
参与约束 指定一个实体的存在是否通过联系依赖于其他实体。 最小基数约束 指定了每个实体参与联系的最小个数。如果某个实体类型中的每个实体都参与到某个联系类型中,则称 完全参与 ,或 存在依赖 。相对的是 部分参与 。
增强的ER模型 ( EER模型 )是加入了语义数据模型特性的改进的ER模型。这些语义数据模型包括人工智能的 知识表示 ,软件工程的 对象建模 等。
对象和对象关系数据库
面向对象的数据库称为 对象数据库 (ODB),其管理系统称为 对象数据管理系统 (Object Data Management Systems, ODMS)。主要概念包括:
- 对象标识,由ODMS生成。
- 类型构造器。如元组、包、集合、列表。
- 封装操作。定义对象结构的同时也应定义其操作。
- 类型层次和类型继承。允许使用类型层次来指定对象类型。
- 多态和运算符重载
- 外延。将某一类型的所有持久对象存储在一个外延里。
带有对象数据库扩展的关系模型称为 对象-关系模型 。
此后,ODMG(object data management group)提出了一系列的ODMG标准,包括ODMG对象模型、对象定义语言(ODL)、对象查询语言(OQL)、对OOPL的绑定。ODMG对象模型的基本构建块为对象和文字,两者都可以有一个复杂的结构其区别在于对象具有标识。
数据库性能
查询处理与优化算法
以下给出一个典型的高级查询处理的过程:
- 扫描器 识别语言标记如SQL关键字、属性名、关系名
- 有效性检查 根据被检索的数据库模式,验证有效性
- SQL语句转换为关系代数,生成 查询树 或 查询图
- DBMS通过 查询优化 过程确定一个 执行策略
- 代码生成器 根据上述策略生成代码
- 运行时数据库处理器 编译运行或解释运行查询代码生成查询结果
外排序算法 将处理类似ORDER BY语句,适用于存储在磁盘的大文件。一般采用归并排序:先对每个小文件进行排序,然后进行归并。 归并度 定义为每次归并的文件个数。复杂度为 $2b+2b\log_{d_M}n_R$,其中因子 $2$ 为读和写,$b$ 为块数,$n_R$ 为总块数。
选择算法 包括 S1线性搜索 (蛮力查找)、 S2二分查找 (要求比较运算)、 S3a利用索引 、 S3b利用散列键 (只支持候选键)、 S4主索引检索多条记录 、 S5聚簇索引检索多条记录 、 S6辅助索引(B+树)处理相等判断 等。
二路连接 指对两个文件的连接,如果涉及多个文件则称为 多路连接 。算法包括 J1嵌套循环连接 (蛮力)、 J2单循环连接 (要求索引)、 J3排序-归并连接 、 J4分区-散列连接 等。
集合运算 可以采用散列法。
利用关系代数运算,可以将代价较高的 初始查询树 转换为代价较低的 最终查询树 。
事务与并发
根据并发使用的用户数量,DBMS分为 单用户 系统和 多用户 系统。数据库中的并发控制大多是基于 交替并发 理论发展而来。
事务的边界 可以由 开始事务 和 结束事务 来显式定义。根据其行为将事务可以分为 只读事务 和 读写事务 。事务将数据库看做 命名数据项 的集合,数据项大小成为 粒度 。
并发执行可能遇到的问题有:
- 更新丢失。写操作被其他事务覆盖了。
- 暂时更新。可能错误的暂时写在恢复前已经被其他事务读取。
- 错误求和。执行聚集函数时另一个事务更改了某些项。
- 不可重复读。即两次读取得到的值不一致。
可恢复调度 :如果调度S中的事务T读取某个数据X,知道所有写X的事务T'都已提交,T才提交,则调度是 可恢复的 。如果每个事务只读取已提交事务的数据项,则该调度是 无级联的(避免级联回滚的) 。如果最后一个写X的事务提交之前,其他事务都不能读写该项,则称 严格调度 。
严格调度中,撤销事务的写操作很简单,只需要恢复X的 前映像 。
串行的调度 :对于调度S中的每个事务T,如果T的所有操作在调度中都是连续执行的,则调度是串行的。
并发控制中,需要对数据项加锁,包括 二进制锁 (两种状态)、 读写(共享/排他)锁 。在事务执行过程中,可以通过 锁变换 进行 锁升级 或 锁降级 。
两阶段加锁协议 (two-phase locking protocol)包括两个阶段: 扩展 阶段只允许加锁,不能释放任何锁; 收缩 阶段则只能释放锁。可以证明,该协议可以保证调度是可串行的。
上述为 基本的2PL ; 保守2PL 要求预先声明要锁定的数据项,如果某一项不能锁定则该事务不能锁定任何项,这一协议是免死锁的; 严格2PL 要求在提交或撤销前不是放任何排他锁,这一协议不是免死锁的,但可以保证严格调度; 精确2PL 则更具限制性,在提交或撤销前,不释放任何锁。
并发通常会引起 死锁 和 饥饿 。应采取死锁预防和检测方法、FIFS策略等。
数据项的粒度 太大则并发度低;太小则伴随更多的锁和更多的锁操作。引入 多粒度加锁协议(MGL) 允许不同的事务采用不同粒度的锁。
索引加锁 可以解决 幻想问题 :在更新操作同时进行的查询结果是不确定的。类似的还有 谓词加锁 等等。
本文采用 知识共享署名 4.0 国际许可协议(CC-BY 4.0)进行许可,转载注明来源即可: https://harttle.land/2014/05/11/concept-modeling-and-database-design.html。如有疏漏、谬误、侵权请通过评论或 邮件 指出。
