Computer Organization and Design 笔记 - Storage and Other I/O Topics
Introduction
Dependability, Reliability, and Availability
Dependability is the quality of delivered service such that reliance can justifiably be placed on this service.
Reliability is a measure of the continuous service accomplishment(or, equivalently, of the time to failure) from a reference point.
mean time to failure(MTTF) is a reliability measure. annual failure rate(AFR) is the percentage of devices that would be expected to fail in a year for a given MTTF. Service interruption is measured as mean time to repair(MTTR). Mean time between failures(MTBF) is simply the sum of MTTF and MTTR.
Availability is a measure of service accomplishment with respect to the alternation between the two states of accomplishment and interruption.
Availability = MTTF / MTBF
3 ways to improve MTTF:
- Fault avoidance: preventing fault occurrence by construction.
- Fault tolerance: using redundancy to allow the service to comply with the service specification despite faults occurring, which applies primarily to hardware faults.
- Fault forecasting: predicting the presence and creation of faults, which applies to hardware and software faults, allowing the component to be replaced before it fails.
Disk Storage
nonvolatile
Storage device where data retins its value even when power is removed.
track
One of thousands of concentric circles that makes up the surface of a magnetic disk.
sector
One of the segments that make up a track on a magnetic disk; a sector is the smallest amount of information that is read or written on a disk.
Originally, all tracks had the same number of sectors and the same number of bits. With the introduction of zone bit recording(ZBR) , disk drives changed to a varying number of sectors per track. Thus increasing the drive capacity.
cylinder
Cylinder referes to all the tracks under the heads at a given point on all surfaces.
Seek time
The time for the process of positioning a read/write head over the proper track on a disk.
Rotational latency
Also called rotational delay , the time required for the desired sector of a disk to rotate under the read/write head; usually assumed to be half the rotation time.
Transfer time
Transfer time is the time to transfer a block of bits.
Disk controller usually handles the detailed control of the disk and the transfer between the disk and the memory. Controller time is the overhead the controller imposes in performing an I/O access.
Fash Storage
NOR flash : storage cell is similiar to a standard NOR gate. Typically used for BIOS memory.
NAND flash : offers greater storage density, but memory could only be read and written in blocks as wiring needed for random accesses was removed. Typically used for USB key.
wear leveling
To cope with bit wearing out, most NAND flash products include a controller to spread the writes by remaapping blocks that have been written many times to less trodden blocks.
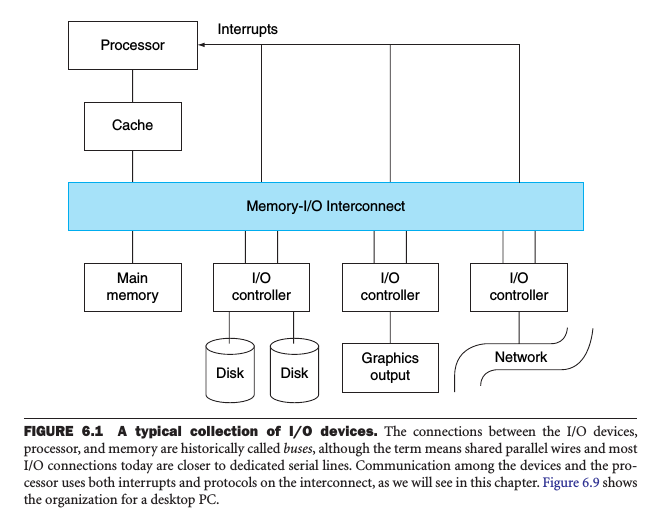
Connecting Processors, Memory, and I/O Devices
processor-memory bus
A bus that connects processor and memory and that is short, generally high speed, and matched to the memory system so as to maximize memory-processor bandwidth.
I/O bus
By contrast, I/O bus can be lengthy, can have many types of devices connected to them, and often have a wide range in data bandwidth of the devices connected to them.
backplane bus
A bus that is designed to allow processors, memory, and I/O devices to coexist on a single bus.
I/O buses donot typically interface directly to the memoty but use either a processor-memory or a backplane bus to connect to memory.
I/O transaction
A sequence of operations over the interconnect that includes a request and may include a response, either of which may caryy data. A transaction is initiated by a single request and may take many individual bus operations.
Synchronous bus
A bus that includes a clock in the control lines and a fixed protocol for communicating that is relative to the clock.
Asynchronous interconnect
Uses a handshaking protocol for coordinating usage rather than a clock; can accommodate a wide variety of devices of differing speeds.
handshaking protocol
A series of steps used to coordinate asynchronous bus transfers in which the sender and receiver proceed to the next step only when both parties agree that the current step has been completed.
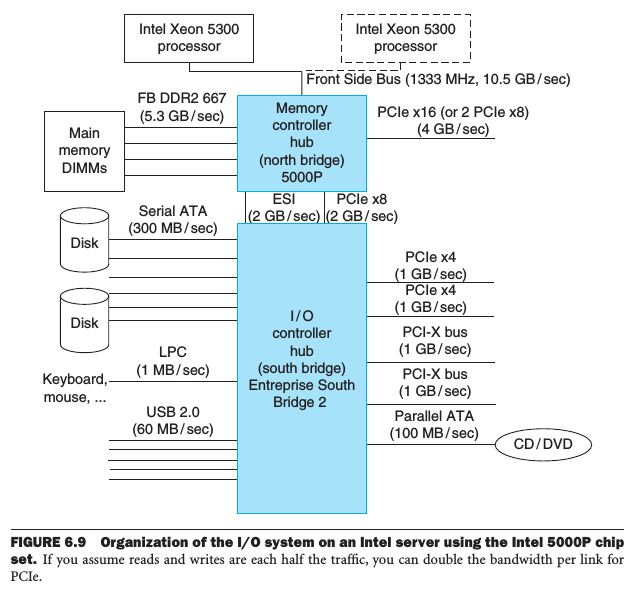
The I/O Interconnects of the x86 Processors
north bridge
The chip for memory controller hub next to the processor.
south bridge
The one connected to north bridge, witch is the I/O controller hub.
Interfacing I/O Devices to the Processor, Memory, and Operating System
Giving commands to I/O devices
memory-mapped I/O
An I/O scheme in which portions of address space are assigned to I/O devices, and reads and writes to those addresses are interpreted as commands to the I/O device.
Communicating with the Processor
- polling : The process of periodically checking the status of an I/O device to determine the need to service the device.
- Interrupt-driven I/O : An I/O scheme that employs interrupts to indicate to the processor that an I/O device needs attention.
Transferring the Data between a Device and Memory
- Use the processor to transfer data between a device and memory based on polling.
- Make the transfer of data interrupt friven.
- direct memory access (DMA) : Having the device controller transfer data directly to ro from the memory without involving the processor.
I/O Performance Measures
transaction processing
A type of application that involves handing small short operations(called transactions) that typically require both I/O and computation. Transaction processing applications typically have both response time requirements and throughput performance.
I/O Rate
Performance measure of I/Os per unit time, such as reads per second.
data rage
Performance measure of bytes per unit time, such as GB/sec.
Designing and I/O System
General approaches:
- Find the weakest link in the I/O system, which will constrain the design.
- Configure this component to sustain the required bandwidth.
- Determine the requirements for the rest of the system and configure them to support this bandwidth.
Parallelism and I/O: Redundant Arrays of Inexpensive Disks
redundant arrays of inexpensive disks (RAID)
An organization of disks that uses an array of small and inexpensive disks so as to increase both performance and reliability.
No Redundancy (RAID 0)
Simply spreading data over multiple disks, called striping.
Mirroring (RAID 1)
Writing the identical data to multiple disks to increase data availability.
Error Detecting and Correcting Code (RAID 2)
RAID 2 borrows an error detection and correction scheme most often used for memories.
Bit-Interleaved Parit (RAID 3)
protection group is the group of data disks or blocks that share a common check disk or block. The cost of higher availability can be reduced to 1/n, where n is the number of disks in a protection group.
Block-Interleaved Parity (RAID 4)
The parity is stored as blocks and associated with a set of data blocks.
Distributed Block-Interleaved Parity (RAID 5)
To fix the parity-write bottleneck, the parity information can be spread throughout all the disks so that there is no single bottleneck for writes.
P+R Redundancy (RAID 6)
When a single failure correction is not sufficient, parity can be generalized to have a second calculation over the data and another check disk of information. The second check block allows recovery from a second failure.
Fallacies and Pitfalls
Fallacy: The rated mean time to failure of disks is almost 140 years, so disks practically never fail.
MTTF is calculated by putting thousands of disks in a room, run them for a few months, and count the number that fail.
The annual failure rate (AFR) is a more useful measure.
Fallacy: A GB/sec interconnect can transfer 1 GB of data in 1 second.
- Generally cannot use 100% of any computer resource.
- The definition of a GB of storage ($2^30$) and a GB persecond of bandwidth ($10^9$) donot agree.
OSs are the best place to schedule disk accesses.
Since the disk knows the actual mapping of the logical addresses onto a physical geometry of sectors, tracks, and surfaes, it can reduce the rotational and seek latencies by rescheduling.
Pitfall: Using the peak transfer rate of a portion of the I/O system to make performance projections or performance comparisons.
The peak performance is based on unrealistic assumptions about the system or are unattainble because of other system limitations.
本文采用 知识共享署名 4.0 国际许可协议(CC-BY 4.0)进行许可,转载注明来源即可: https://harttle.land/2014/02/23/computer-design-io.html。如有疏漏、谬误、侵权请通过评论或 邮件 指出。
